背景
Ollama 作为一款备受欢迎的本地大模型部署工具,一直以来主要专注于文本生成能力。虽然在之前的版本中已经初步支持了多模态模型,但由于底层 llama.cpp 实现的局限性,与各大厂商最新多模态模型的兼容进展一直较为缓慢。 在这一背景下,Ollama 团队在最新的 0.7 版本中对核心引擎进行了全面重构,彻底解决了多模态模型适配的技术瓶颈。这次重构不仅优化了底层架构,还专门设计了灵活的接口,能够快速、高效地接入各种多模态模型,标志着 Ollama 从专注文本生成向全面多模态能力的重大转变。、 在 Ollama 的 GitHub 仓库中,关于多模态和视觉模型支持的 issue 一直是讨论最热烈的话题之一。从最初的功能请求,到各种技术方案的探讨,再到最终的实现,社区成员们展现出了极大的热情和耐心。说实话,笔者关注这个 issue 都快一年了,终于完成支持,不容易啊!
在 Ollama 的 GitHub 仓库中,关于多模态和视觉模型支持的 issue 一直是讨论最热烈的话题之一。从最初的功能请求,到各种技术方案的探讨,再到最终的实现,社区成员们展现出了极大的热情和耐心。说实话,笔者关注这个 issue 都快一年了,终于完成支持,不容易啊!
📱 一行命令,即刻体验顶级多模态模型
Ollama 现已通过全新引擎支持多模态模型,首批支持的视觉模型包括:- 🌟 Qwen 2.5 VL - 阿里巴巴开源的中英双语视觉模型
- 🌟 Meta Llama 4 - 11B 参数的顶尖视觉语言模型
- 🌟 Google Gemma 3 - 谷歌最新开源的多模态能力
- 🌟 Mistral Small 3.1 - 性能与体积平衡的优质选择
- 以及更多持续更新中…
💡 能力展示:图像理解与分析
📊 Qwen 2.5 VL:中文 OCR 与文档处理专家
这里使用 7b 的小模型进行准确性测试
📑 业务价值:支持多语言文字识别、文档信息提取,特别优化中文处理能力实际应用案例 1:支票信息提取

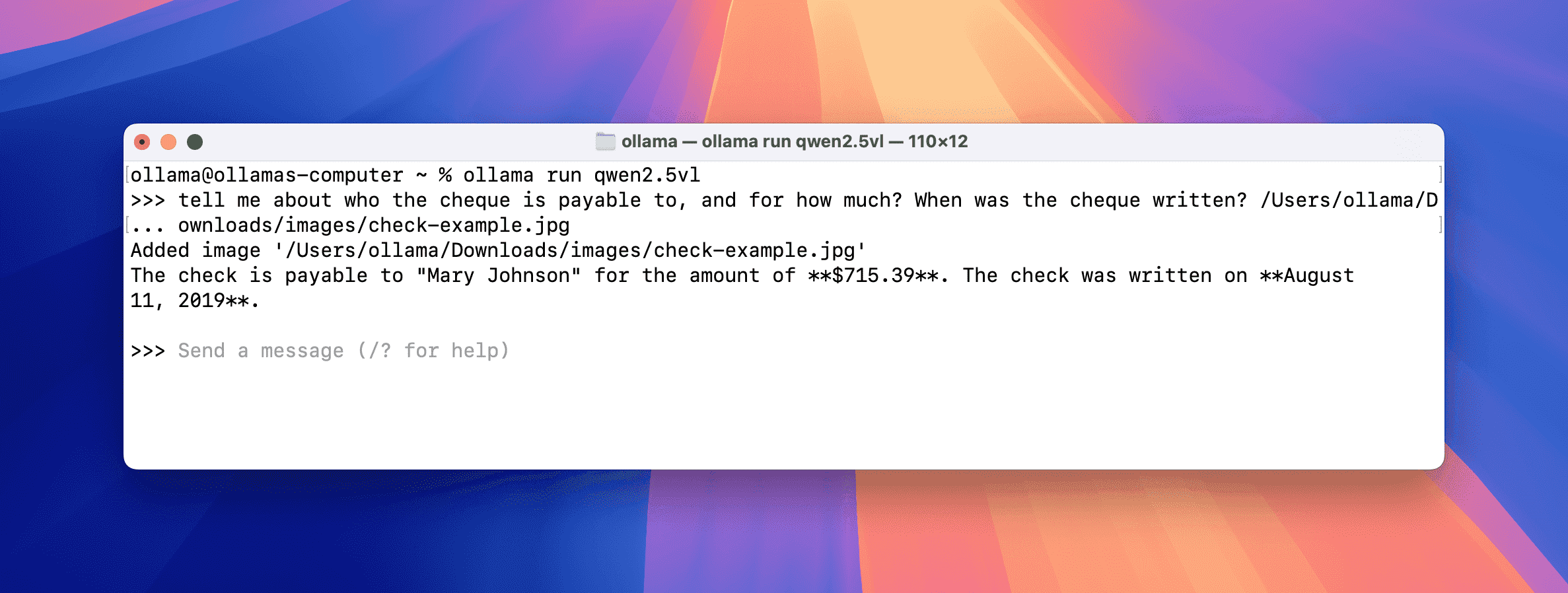 在 PIG AI 应用开发平台中,您可以无缝集成本地部署的 Ollama Qwen 2.5 VL 模型,作为强大的视觉处理引擎。该集成支持一键解析图片附件中的各类信息,作为 AI 交互的上下文补充。
在 PIG AI 应用开发平台中,您可以无缝集成本地部署的 Ollama Qwen 2.5 VL 模型,作为强大的视觉处理引擎。该集成支持一键解析图片附件中的各类信息,作为 AI 交互的上下文补充。
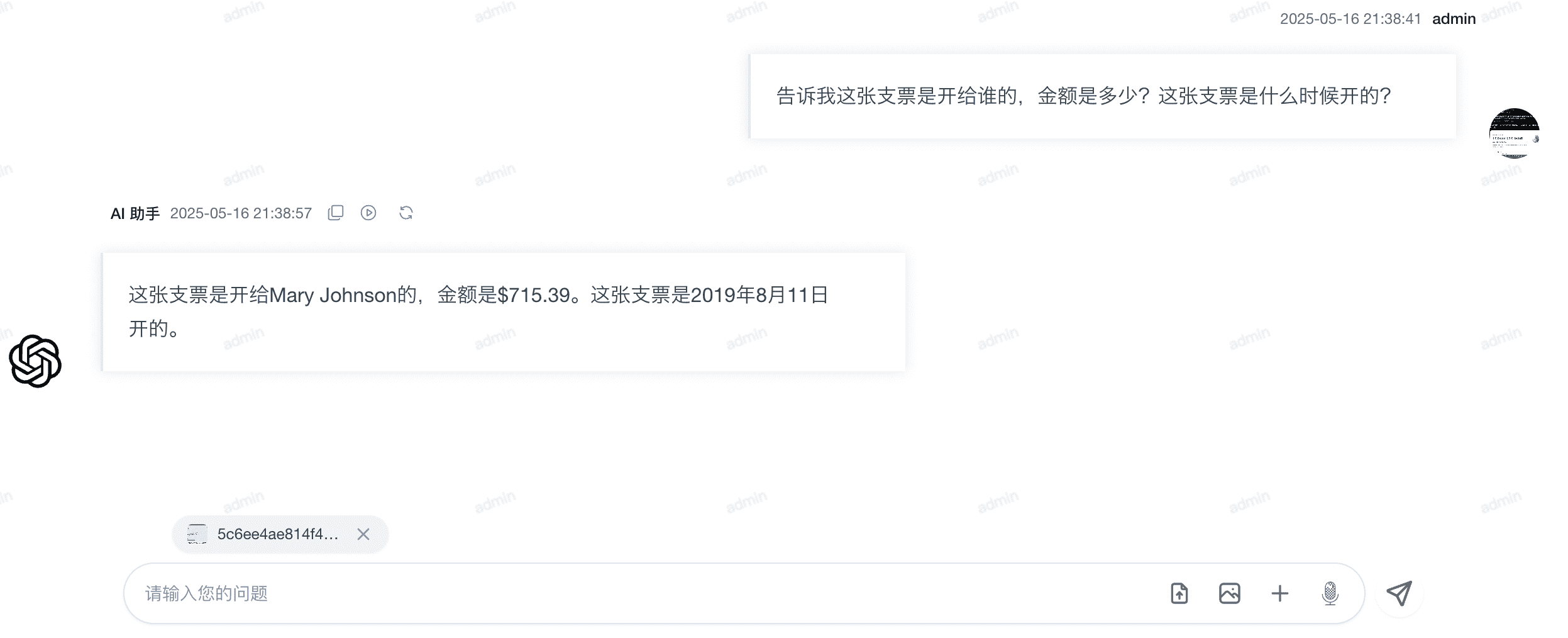 通过结合 Qwen 2.5 VL 识别图像中的文字,PIG AI 将非结构化信息转换为结构化数据,便于系统处理和分析。
通过结合 Qwen 2.5 VL 识别图像中的文字,PIG AI 将非结构化信息转换为结构化数据,便于系统处理和分析。
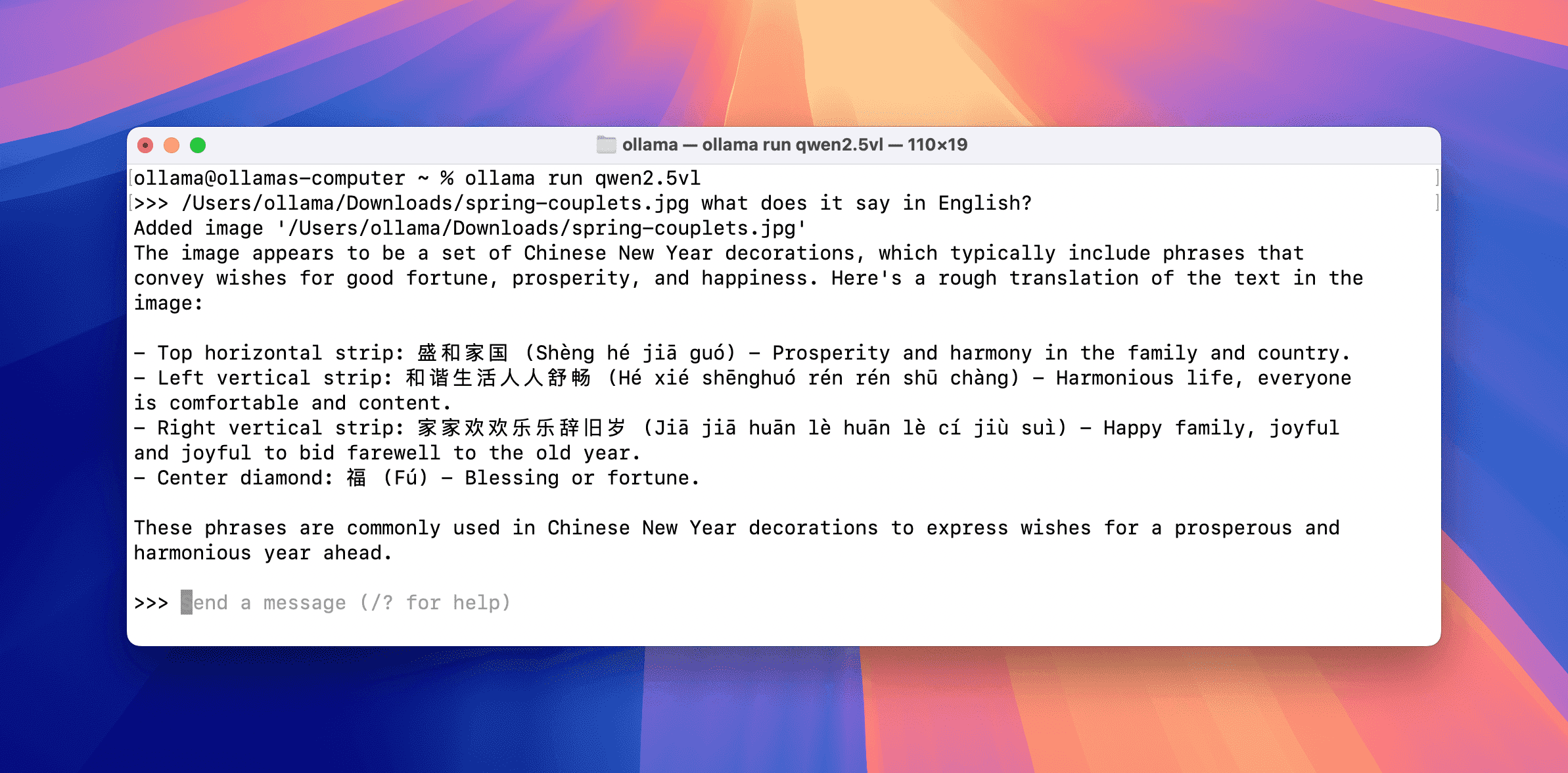
 实际应用案例 2:中文春联识别与翻译
实际应用案例 2:中文春联识别与翻译

⚙️ 0.7 版本全新引擎的优势
🚀 技术升级:从纯文本到全面多模态,Ollama 迈出了重要一步此前,Ollama 依赖 ggml-org/llama.cpp 项目支持模型,重点在易用性和模型可移植性上。随着各大 AI 实验室发布越来越多的多模态模型,我们开发了全新引擎,使多模态成为一等公民,并与 GGML 张量库深度合作。

🛠️ 核心技术突破
1️⃣ 模型模块化设计
- 每个模型”影响范围”限制在自身内部
- 提高系统可靠性
- 降低开发者集成新模型的难度
- 文本解码器和视觉编码器独立执行
2️⃣ 图像处理精准优化
- 添加元数据提高大图像处理准确性
- 智能控制因果注意力机制
- 优化图像嵌入批处理策略
- 严格遵循原始模型设计与训练方式
3️⃣ 内存智能管理
- 图像缓存:处理后智能保留,提高后续提示速度
- 内存估计与 KV 缓存优化:与硬件厂商深度合作
- 模型特定优化:
- Gemma 3 的滑动窗口注意力机制优化
- Llama 4 特有的分块注意力与二维旋转嵌入支持
🔮 未来发展路线图
- 📏 支持更长的上下文窗口
- 🤔 增强推理与思考能力
- 🔧 实现具有流式响应的工具调用
- 💻 启用计算机控制能力
📣 立即行动
想要在本地部署强大的多模态 AI 能力?只需几个简单步骤:- 访问 Ollama 官网 下载最新版本
- 使用一行命令拉取你喜欢的多模态模型
- 开始体验本地 AI 视觉能力!